HTML to PDF renderers: A simple comparison
Monday, March 25, 2024
tl,dr; Converting HTML to PDF is a common challenge in web development. We compared different libraries offering such service in order to better understand their strengths and weaknesses. We found that Fileforge is the most reliable and easy to use library for this task, especially if you render complex HTML documents.
Introduction
Overview
HTML to PDF conversion is a common requirement in modern web applications. It allows users to save web pages, reports, and other content in a format that is easy to share and print. There are many libraries and services available for converting HTML to PDF, each with its own strengths and weaknesses. In this article, we will compare some of the most popular HTML to PDF renderers in Node.js, including Puppeteer, Playwright, node-html-pdf, and Fileforge.
Contenders: Puppeteer, Playwright, Fileforge, node-html-pdf
For this comparison, we will focus on four libraries: Puppeteer, Playwright, Fileforge, and node-html-pdf. These libraries are widely used in the Node.js ecosystem and offer a range of features for converting HTML to PDF. We will evaluate each library based on its ease of use, performance, and compatibility with different HTML and CSS features.
- Puppeteer is a Node.js library developed by Google that provides a high-level API for controlling headless Chrome or Chromium. It is commonly used for web scraping, automated testing, and generating PDFs from HTML.
- Developed by Microsoft, Playwright is a Node.js library that provides a high-level API for controlling headless browsers. It is similar to Puppeteer but supports multiple browser engines, including Chromium, Firefox, and WebKit.
- node-html-pdf is a Node.js library that converts HTML to PDF using PhantomJS, a headless browser. It is a simple and lightweight library that is easy to use but may not support all HTML and CSS features. node-html-pdf is no longer actively maintained, but it is still widely used in several legacy projects.
- Fileforge is a complete API solution offering PDF generations and other kind of operations on PDFs (merging, splitting, signing, form filling, etc.). It is a high-level API that abstracts the complexity of PDF generation and provides a simple and intuitive interface for converting HTML to PDF. Fileforge is designed to be fast, reliable, and easy to use, making it a good choice for developers who need to generate PDFs from HTML. It also come with it’s own open-source library react-print-pdf, a UI kit for PDFs.
The testing environment
For this comparison we decided to use a simple example of HTML document with some specific CSS styles (fonts, margins, etc.) and a header and footer. We used the react-print-pdf library to design the HTML document using React components. Especially, we re-used the advanced invoice with QR code template from the reac-print-pdf library. We then converted this HTML document to PDF using each of the four libraries and compared both the process required to generate the PDF and the quality of the output. We run the experiment on a MacBook Pro with Apple M1 Pro chip, 32 GB of RAM, using Node.js v20.11.0. We used chromium as the browser for Puppeteer and Playwright.
Designing the HTML document with react-print-pdf
Before diving into the comparison, let’s take a look at the HTML document we will be using for testing. As mentioned earlier, we used the advanced invoice with QR code template from the react-print-pdf library. This template includes a header, footer, and body with various CSS styles and components. The react-print-pdf has been specifically created to design PDFs using React components, making it easy to create complex layouts and styles for PDF documents. But with complex layouts come complex rendering requirements, which is why we chose this template for our comparison. Here is a quick overview of the template invoice.tsx:
| 1 | import { Footnote, PageBottom, Tailwind, CSS } from "@fileforge/react-print"; |
| 2 | import { QRCodeSVG } from "qrcode.react"; |
| 3 | import { ArrowRightIcon } from "@heroicons/react/20/solid"; |
| 4 | export const Invoice = () => { |
| 5 | return ( |
| 6 | <Tailwind> |
| 7 | <CSS> |
| 8 | {`@import url('https://fonts.googleapis.com/css2?family=Inter:wght@400;700&display=swap'); |
| 9 | |
| 10 | @page { |
| 11 | size: a4; |
| 12 | margin: .75in .75in 1in .75in; |
| 13 | } |
| 14 | `} |
| 15 | </CSS> |
| 16 | <div className="font-[inter] text-slate-800"> |
| 17 | <div className="bg-slate-100 -z-10 absolute -bottom-[1in] -right-[.75in] -left-[.75in] rounded-t-[.75in] h-[20vh]"></div> |
| 18 | <PageBottom> |
| 19 | <div className="text-xs text-slate-400 border-t border-t-slate-300 py-4 mt-4 flex border-b border-b-slate-300"> |
| 20 | <div>Invoice #1234</div> |
| 21 | [...] |
As you can see, we have the following components in the template:
- Tailwind: A component that allows you to define Tailwind CSS styles for the document
- CSS: A component that allows you to define custom CSS styles for the document (here specifically the fonts, format and margins).
- PageBottom: A component that defines the footer of the document.
- Footnote: A component that defines additional information at the bottom of the document.
This template is designed to be visually appealing and includes various CSS styles, fonts, and components. We will use this template to test the HTML to PDF renderers and evaluate their performance and output quality.
Once you have design your document using React, you can easily get the HTML using the compile function from the react-print-pdf library:
| 1 | import { compile } from "@fileforge/react-print"; |
| 2 | import { Invoice } from "./invoice.tsx"; |
| 3 | |
| 4 | (async () => { |
| 5 | const html = await compile(<Invoice />); |
| 6 | })(); |
Rendering the HTML document to PDF
Now that we have our HTML document ready, let’s move on to rendering it to PDF using the four libraries: Puppeteer, Playwright, Fileforge, and node-html-pdf.
Fileforge
Fileforge library offers a simple and intuitive API for converting HTML to PDF. You can get your PDF in just one line of code:
| 1 | import { Fileforge } from "@fileforge/client"; |
| 2 | |
| 3 | const fileforge = new Fileforge("FILEFORGE_API_KEY"); |
| 4 | |
| 5 | const { file } = await fileforge.render({ |
| 6 | html, |
| 7 | test: false, |
| 8 | save: false, |
| 9 | }); |
Note that Fileforge offers 2 types of rendering: dev mode and production mode. The dev mode is controlled by the test parameter and allow you to add a watermark on the PDF so you don’t have to pay for the rendering. In production mode, the watermark is removed. You can generate up to 500 documents per month for free with Fileforge, before moving to a “pay-as-you-go” plan or “enterprise” plan. Also, the save parameter allows you to save the PDF on the Fileforge platform, so you can access it later or share it with other using a secured link.
Puppeteer and Playwright
Puppeteer and Playwright are both headless browser automation libraries that allow you to control a headless browser and generate PDFs from HTML. The rendering process is similar for both libraries. We decompose the process as follows:
- Launch a headless browser instance (Chromium in our case).
- Create new context.
- Create a new page.
- Set the content of the page to the HTML document.
- Generate the PDF from the page content.
- Close the browser instance.
Here is the code to render the HTML document to PDF using Playwright:
| 1 | import playwright from "playwright"; |
| 2 | |
| 3 | const browserPlaywright = await playwright.chromium.launch(); |
| 4 | const contextPlaywright = await browserPlaywright.newContext(); |
| 5 | const pagePlaywright = await contextPlaywright.newPage(); |
| 6 | await pagePlaywright.setContent(html, { waitUntil: "networkidle" }); |
| 7 | await pagePlaywright.pdf({ path: `./document_playwright.pdf`, format: "A4" }); |
| 8 | await browserPlaywright.close(); |
and here is the code to render the HTML document to PDF using Puppeteer:
| 1 | import puppeteer from "puppeteer"; |
| 2 | |
| 3 | const browserPuppeteer = await puppeteer.launch(); |
| 4 | const pagePuppeteer = await browserPuppeteer.newPage(); |
| 5 | await pagePuppeteer.setContent(html, { waitUntil: "networkidle" }); |
| 6 | await pagePuppeteer.pdf({ path: `./document_puppeteer.pdf`, format: "A4" }); |
| 7 | await browserPuppeteer.close(); |
Note that for both libraries, we set the waitUntil option to networkidle to ensure that the page is fully loaded before generating the PDF. We also set the format option to A4 to specify the page format of the PDF. It complexify the process and make it less intuitive than Fileforge, but without doing it, the PDF generated may not be correct at all.
Also, note that we had to modify the CSS tag of the template, especially the way we import fonts, to make it work with Puppeteer and Playwright. Especially, we hade to change display=block to display=swap in the font import. This is a common issue with Puppeteer and Playwright, as they need to load the fonts before rendering the PDF. Without such modification, the fonts are not loaded and the PDF is completely broken.
node-html-pdf
node-html-pdf is a simple library that converts HTML to PDF using PhantomJS, a headless browser. The rendering process is straightforward and does not require launching a headless browser instance. The code used to render the HTML document to PDF using node-html-pdf is as follows:
| 1 | import pdf from "html-pdf"; |
| 2 | |
| 3 | pdf.create(html).toFile("./document_html-pdf.pdf", function (err, res) { |
| 4 | if (err) return console.log(err); |
| 5 | console.log(res); |
| 6 | }); |
The process is simple and easy to use, but the library is no longer actively maintained and may not support all HTML and CSS features. We will see in the results section if it can handle the complex layout of our HTML document.
Results
In the following section we will observe the results of the rendering process using the four libraries. We evaluate the quality of the PDF output, the ease of use of the libraries, and the performance in term of time and ressources. In order to have somehow robust results, we run the experiment 100 times for each library.
Performance
We measured the time taken to render the HTML document to PDF using each of the four libraries using a simple console.time and console.timeEnd function. In order to measure the memory usage we used the process.memoryUsage() method and we make sure to force garbage collection using the global.gc() method and the --expose-gcflag when running the analysis .Here are the results:
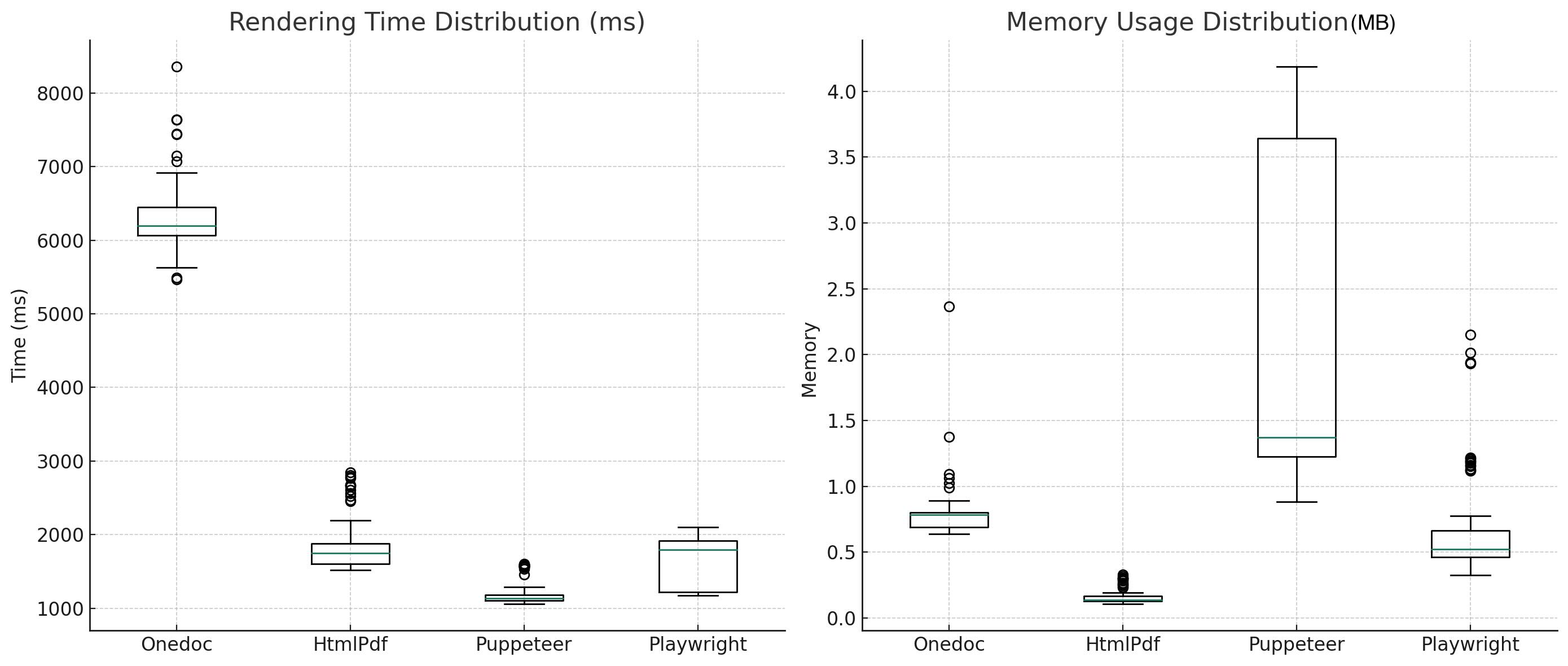
These distributions provide deeper insights into the consistency and reliability of each renderer. As expected, it takes longer to render the PDF using Fileforge as it performs different API calls while other libraries are running locally. On the other hand, we observe that the memory usage is very high for Puppeteer, which is not suprising as it required to launch a headless browser instance. We can also directly see the improvement between Playwright and Puppeteer, as Playwright — while being also a headless browser — is more optimized and use less memory.
However, this performance analysis is only worth considering the quality of the output and the ease of use of the libraries. Let’s dive into these two aspects.
Output quality and ease of use
This is where the real difference between the libraries comes into play. We evaluated the quality of the PDF output generated by each library by comparing the visual appearance of the PDFs. We also evaluated the ease of use of the libraries by looking at the code required to render the PDF and the complexity of the process.
Ease of use
We described the process to render the PDF using each library in the previous section. This is our opinion for each library:
- node-html-pdf: the library is simple and easy to use, one simple command and you get your PDF. However, the library is no longer maintained and we expect to have issue with complex layouts. Also, even if the HTML document include already all information about the layout, you may have to add some
optionto make it work correctly as shown in the .README. So while being simple, it requires manual fintuning for each document. - Puppeteer and Playwright: the libraries are powerful and offer a lot of features, but they are complex to use and require launching a headless browser instance. The rendering process is not intuitive and requires additional steps to ensure that the PDF is generated correctly. As mentioned, modifying the CSS of the template was required to make it works. You also have to handle the headless browser instance correctly by adding waiting time, etc. And most importantly, even if all the information are provided in the HTML (fonts, margins, etc.), you have to add specify option to the rendering process such as the
formatof the page,printBackground,displayHeaderFooter, etc. This makes the process complex and error-prone. - Fileforge: the library is simple and easy to use, you just have to provide the HTML document and you get your PDF. The library abstracts the complexity of the rendering process and provides a simple and intuitive interface for converting HTML to PDF. You don’t have to worry about launching a headless browser instance or modifying the CSS of the template. It is able to render complex layouts without any issue and specific options, as it retrieve all the information from the HTML document.
Quality of the output
We evaluated the quality of the PDF output generated by each library by comparing the visual appearance of the PDFs. Especially we focused on the consistency betweem each run (do you get the same PDF each time you run the code) and the quality of the rendering (are the fonts correctly displayed, are the margins respected, etc.). Here are the results.
Fileforge
- Consistency: The PDF generated by Fileforge is consistent across runs, producing the same output each time.
- Quality: The PDF obtained is correct and respect the layout of the HTML document, without any issue. The fonts are correctly loaded, the margins are respected, the header and footer are displayed correctly, and the layout is correct.
PDF generated by Fileforge:
node-html-pdf
- Consistency: The PDF generated by node-html-pdf is consistent across runs, producing the same output each time.
- Quality: The PDF obtained does not look at all like the HTML document we provided. Some of the issue we observed are:
- The margins are not respected.
- The header and footer are not displayed.
- The layout is broken.
- Footer and header are not displayed.
- Tailwind style are not applied.
PDF generated by node-html-pdf:
Puppeteer
- Consistency: The PDF generated by Puppeteer is inconsistent across runs, producing different outputs each time. Especially, the font is not loaded correctly and therefor nothing is displayed in the PDF.
- Quality: Letting aside the issue with the consistency, the PDF obtained is still not correct. While being better than the result obtained with node-html-pdf, the results is still not satisfying enough. Some of the issue we observed are:
- Tailwind style are not applied correctly.
- The header and footer are not displayed correctly but rather mixed with the content.
- The layout is broken (2 pages instead of 1).
PDF generated by Puppeteer(left: when the font is not loaded, right: when the font is loaded):
Playwright
- Consistency: The PDF generated by Playwright is consistent across runs, which shows the improvement made by Playwright compared to Puppeteer. The font is loaded correctly and the PDF is the same each time.
- Quality: The PDF obtained is correct, but still not perfect. The issues are the same as with Puppeteer:
- Tailwind style are not applied correctly.
- The header and footer are not displayed correctly but rather mixed with the content.
- The layout is broken (2 pages instead of 1).
PDF generated by Playwright:
Conclusion
In conclusion, we found that Fileforge is the most reliable and easy to use library for converting HTML to PDF. It offers a simple and intuitive API that abstracts the complexity of the rendering process and provides a consistent and high-quality output. Fileforge is able to render complex layouts without any issue and specific options, making it a good choice for developers who need to generate PDFs from HTML in a professional and reliable way.
Given the inconsistency of the output when using Puppeteer, we would not recommend to use it at all but rather to use Playwright if you want to use a headless browser. It is especially true if you want to produce very simple document without styled components or complex layout. But you’ll still have to finetune the rendering process for each HTML you want to renderer, regardless of the complexity of the layout, which can be time-consuming, error-prone and not intuitive.
Finally, node-html-pdf is not recommended at all, as it does not provide a correct output and is no longer maintained at all.
Although this comparison concentrated on a basic use case and did not explore each criterion in depth, we plan to expand our analysis to include more complex documents and use cases in the future (security, accessibility, performance for high volume, parallel rendering, etc.) Stay tuned:
- Try Fileforge for free.
- Join the community and share your thoughts.
- Contribute to the open-source library.