
PDF Form Handling with Fileforge
Thursday, June 6, 2024
tl;dr: The new Fileforge API allows you to manipulate PDF forms with ease. Learn how to extract, mark, and fill forms programmatically in this blog article.
Introduction
Forms are an essential part of many business processes, from collecting customer information to processing orders. However, handling forms can be a time-consuming and error-prone process, especially when done manually. That’s where Fileforge comes in.
With our latest API update, we’re introducing new endpoints that allow you to extract, mark, and fill PDF forms programmatically. This makes it easier than ever to automate your form handling processes and reduce the risk of errors.
Note that you can also use our SDKs to interact with the API. We currently support Python, Node.js, with more languages coming soon.
What can you do with the new API endpoints?
As of today, we support 3 types of operations on PDF forms:
- Extract: Extract form fields from a PDF document.
- Mark: Mark form fields with comment annotations (debugging mode)
- Fill: Fill form fields with data.
How it works?
We will execute the 3 operations on the following PDF document:

Extracting form fields
Let’s first take a look at how you can set up your payload and make a request to extract form fields from a PDF document.
| 1 | import { readFileSync, writeFileSync } from "fs"; |
| 2 | import { FormData, Blob } from "formdata-node"; |
| 3 | |
| 4 | // set-up the API key and the path to the document |
| 5 | const API_KEY = "XXX-API-KEY-XXX"; |
| 6 | const documentPath = "./form.pdf"; |
| 7 | const documentBuffer = readFileSync(documentPath); |
| 8 | |
| 9 | // create a new FormData object and append the file to it |
| 10 | const payload = new FormData(); |
| 11 | payload.append("file", new Blob([documentBuffer]), "form.pdf"); |
| 12 | |
| 13 | /** |
| 14 | * Detects fields in a programmatic way. Returns a list of all available fields, field types and options (if any). |
| 15 | */ |
| 16 | const detectFields = await fetch("https://api.fileforge.com/pdf/form/detect", { |
| 17 | method: "POST", |
| 18 | body: payload, |
| 19 | headers: { |
| 20 | "X-API-Key": API_KEY, |
| 21 | }, |
| 22 | }); |
| 23 | |
| 24 | // get the fields as JSON |
| 25 | const fields = await detectFields.json(); |
| 26 | |
| 27 | // log the first 20 fields to the console |
| 28 | console.log(fields.slice(0, 20)); |
Note: The you can get you API_KEY from the Fileforge dashboard.
We obtain the following output in the console:
| 1 | [ |
| 2 | { |
| 3 | name: 'undefined', |
| 4 | required: false, |
| 5 | readOnly: false, |
| 6 | locations: [ [Object] ], |
| 7 | type: 'PDFCheckBox', |
| 8 | isChecked: false |
| 9 | }, |
| 10 | { |
| 11 | name: 'Admissions and Records Enrollment Services at', |
| 12 | required: false, |
| 13 | readOnly: false, |
| 14 | locations: [ [Object] ], |
| 15 | type: 'PDFTextField', |
| 16 | isPassword: false, |
| 17 | isRichFormatted: false, |
| 18 | isScrollable: true, |
| 19 | isCombed: false, |
| 20 | isMultiline: false, |
| 21 | isFileSelector: false |
| 22 | }, |
| 23 | { |
| 24 | name: 'Name', |
| 25 | required: false, |
| 26 | readOnly: false, |
| 27 | locations: [ [Object] ], |
| 28 | type: 'PDFTextField', |
| 29 | isPassword: false, |
| 30 | isRichFormatted: false, |
| 31 | isScrollable: true, |
| 32 | isCombed: false, |
| 33 | isMultiline: false, |
| 34 | isFileSelector: false |
| 35 | }, |
| 36 | ... |
| 37 | ] |
As you can see, the API returns a list of all available fields in the PDF document, along with their types and options. There are different types of fields, such as PDFCheckBox and PDFTextField, each with its own set of properties. You can find the full list of field types and properties in the API documentation.
Also, you can notice that the first field has a name of undefined. This is because the field does not have a name attribute in the PDF document. This is why we developed the ‘mark’ operation, to help you identify fields that are not named. Let’s see how it works.
Marking form fields
Here we will mark the fields with a comment annotation and a green square. This will help you identify fields that are not named in the PDF document.
| 1 | /** |
| 2 | * Use this to write a debug PDF with comments highlighting each field name and position. |
| 3 | * This is best open in Acrobat Reader. Note: the fields themselves may hide the highlight. |
| 4 | * To view the tags anyway, open the comments pane in Acrobat Reader. |
| 5 | */ |
| 6 | const markFields = await fetch("https://api.fileforge.com/pdf/form/mark", { |
| 7 | method: "POST", |
| 8 | body: payload, |
| 9 | headers: { |
| 10 | "X-API-Key": API_KEY, |
| 11 | }, |
| 12 | }); |
| 13 | |
| 14 | if (markFields.status !== 201) { |
| 15 | throw new Error(await markFields.text()); |
| 16 | } |
| 17 | |
| 18 | // write the debug PDF to disk |
| 19 | writeFileSync("./form-debug.pdf", Buffer.from(await markFields.arrayBuffer())); |
The resulting PDF document will look like this:
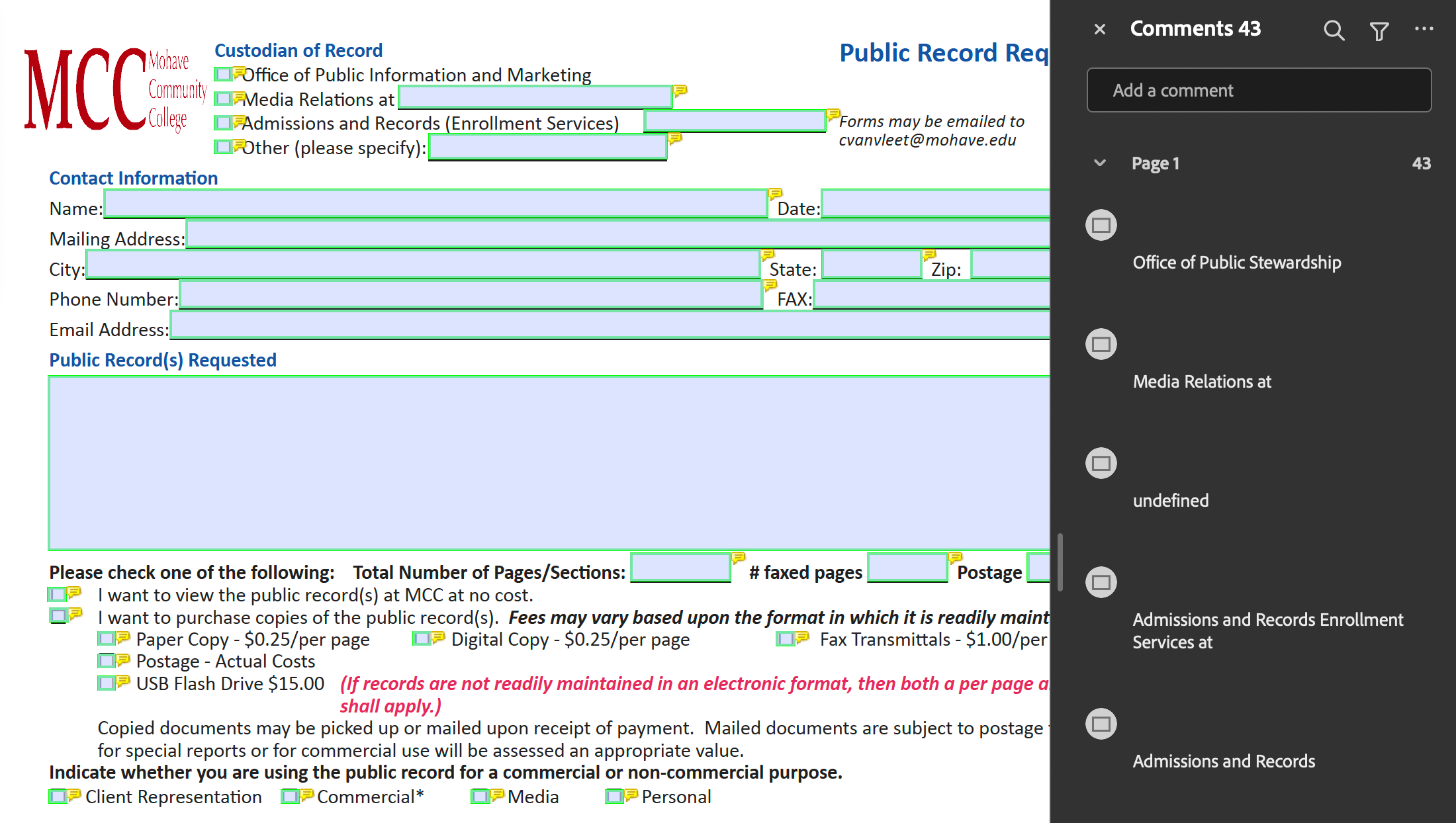
As you can see, each field is marked with a comment annotation and a green square. This makes it easy to identify fields that are not named in the PDF document.
Filling form fields
Finally, let’s see how you can fill form fields with data programmatically.
| 1 | payload.append( |
| 2 | "options", |
| 3 | new Blob( |
| 4 | [ |
| 5 | JSON.stringify({ |
| 6 | /** |
| 7 | * The fields to fill. The name must match the field name exactly. There are various options depending on the field type. |
| 8 | */ |
| 9 | fields: [ |
| 10 | { |
| 11 | name: "Name", |
| 12 | type: "PDFTextField", |
| 13 | value: "Auguste Lefevre Grunewald", |
| 14 | }, |
| 15 | { |
| 16 | name: "Office of Public Stewardship", |
| 17 | type: "PDFCheckBox", |
| 18 | checked: true, |
| 19 | }, |
| 20 | { |
| 21 | name: "Phone Number", |
| 22 | type: "PDFTextField", |
| 23 | value: "+1 415 123-1234", |
| 24 | }, |
| 25 | ], |
| 26 | }), |
| 27 | ], |
| 28 | { |
| 29 | type: "application/json", |
| 30 | } |
| 31 | ) |
| 32 | ); |
| 33 | |
| 34 | // fill the form |
| 35 | const filledForm = await fetch("https://api.fileforge.com/pdf/form/fill", { |
| 36 | method: "POST", |
| 37 | body: payload, |
| 38 | headers: { |
| 39 | "X-API-Key": API_KEY, |
| 40 | }, |
| 41 | }); |
| 42 | |
| 43 | // check for errors |
| 44 | if (filledForm.status !== 201) { |
| 45 | throw new Error(await filledForm.text()); |
| 46 | } |
| 47 | |
| 48 | // write the filled form to disk |
| 49 | writeFileSync("./form-filled.pdf", Buffer.from(await filledForm.arrayBuffer())); |
The resulting PDF document will look like this:

As you can see, the form fields have been filled with the data we provided. This makes it easy to automate the process of filling out forms and reduce the risk of errors.
For other types of fields and options (e.g. checkboxes, radio buttons, dropdowns), please refer to the API documentation.
Conclusion
In this blog post, we’ve shown you how to use the new Fileforge API endpoints to extract, mark, and fill PDF forms programmatically. This makes it easier than ever to automate your form handling processes and reduce the risk of errors.
We hope you found this article helpful. If you have any questions or feedback, please feel free to reach out to us. We’re always looking for ways to improve our API and make it more useful for our users.
Happy coding!
- Try the new Fileforge API endpoints for form handling here. It’s free!
- Join the Fileforge community on Discord and share your feedback with us.
- Contribute to the open-source library

